how to draw a 3d floating number 8
A Tutorial on Data Representation
Integers, Floating-point Numbers, and Characters
Number Systems
Homo beings use decimal (base ten) and duodecimal (base of operations 12) number systems for counting and measurements (probably considering we accept 10 fingers and two big toes). Computers use binary (base of operations 2) number organisation, as they are made from binary digital components (known as transistors) operating in two states - on and off. In computing, nosotros also utilise hexadecimal (base of operations 16) or octal (base 8) number systems, every bit a compact grade for representing binary numbers.
Decimal (Base of operations x) Number Arrangement
Decimal number system has 10 symbols: 0, 1, ii, 3, four, 5, half-dozen, 7, 8, and 9, called digits. Information technology uses positional notation. That is, the to the lowest degree-significant digit (right-virtually digit) is of the order of 10^0 (units or ones), the 2nd right-well-nigh digit is of the society of ten^1 (tens), the third right-most digit is of the gild of ten^ii (hundreds), so on, where ^ denotes exponent. For instance,
735 = 700 + 30 + 5 = vii×x^2 + 3×ten^1 + 5×10^0
We shall announce a decimal number with an optional suffix D if ambiguity arises.
Binary (Base 2) Number Arrangement
Binary number system has ii symbols: 0 and i, chosen $.25. It is besides a positional notation, for example,
10110B = 10000B + 0000B + 100B + 10B + 0B = one×2^iv + 0×ii^3 + one×ii^2 + 1×2^one + 0×ii^0
Nosotros shall denote a binary number with a suffix B. Some programming languages denote binary numbers with prefix 0b or 0B (e.g., 0b1001000), or prefix b with the bits quoted (east.grand., b'10001111').
A binary digit is called a bit. 8 $.25 is called a byte (why 8-bit unit? Probably considering eight=2three ).
Hexadecimal (Base sixteen) Number Organisation
Hexadecimal number system uses 16 symbols: 0, 1, 2, 3, iv, 5, 6, vii, 8, 9, A, B, C, D, E, and F, called hex digits. It is a positional notation, for example,
A3EH = A00H + 30H + EH = 10×16^2 + 3×16^i + 14×16^0
Nosotros shall announce a hexadecimal number (in short, hex) with a suffix H. Some programming languages denote hex numbers with prefix 0x or 0X (e.g., 0x1A3C5F), or prefix x with hex digits quoted (due east.yard., x'C3A4D98B').
Each hexadecimal digit is likewise called a hex digit. Most programming languages have lowercase 'a' to 'f' likewise as uppercase 'A' to 'F'.
Computers uses binary system in their internal operations, as they are congenital from binary digital electronic components with two states - on and off. Even so, writing or reading a long sequence of binary $.25 is cumbersome and fault-prone (attempt to read this binary string: 1011 0011 0100 0011 0001 1101 0001 1000B, which is the same as hexadecimal B343 1D18H). Hexadecimal arrangement is used as a meaty form or shorthand for binary $.25. Each hex digit is equivalent to 4 binary bits, i.east., shorthand for 4 bits, as follows:
| Hexadecimal | Binary | Decimal |
|---|---|---|
| 0 | 0000 | 0 |
| 1 | 0001 | ane |
| 2 | 0010 | 2 |
| 3 | 0011 | 3 |
| 4 | 0100 | 4 |
| 5 | 0101 | five |
| 6 | 0110 | half dozen |
| vii | 0111 | 7 |
| 8 | 1000 | 8 |
| 9 | 1001 | 9 |
| A | 1010 | 10 |
| B | 1011 | eleven |
| C | 1100 | 12 |
| D | 1101 | 13 |
| E | 1110 | xiv |
| F | 1111 | xv |
Conversion from Hexadecimal to Binary
Supersede each hex digit past the 4 equivalent bits (as listed in the above table), for examples,
A3C5H = 1010 0011 1100 0101B 102AH = 0001 0000 0010 1010B
Conversion from Binary to Hexadecimal
Starting from the right-virtually scrap (to the lowest degree-significant bit), replace each group of 4 bits by the equivalent hex digit (pad the left-most bits with zero if necessary), for examples,
1001001010B = 0010 0100 1010B = 24AH 10001011001011B = 0010 0010 1100 1011B = 22CBH
It is important to note that hexadecimal number provides a compact form or shorthand for representing binary $.25.
Conversion from Base of operations r to Decimal (Base of operations x)
Given a northward-digit base r number: dn-1dnorth-twoddue north-iii...d2doned0 (base r), the decimal equivalent is given by:
dn-one×rn-1 + dnorth-two×rnorthward-two + ... + d1×r1 + d0×r0
For examples,
A1C2H = x×16^3 + 1×16^2 + 12×16^1 + 2 = 41410 (base x) 10110B = 1×2^4 + ane×2^two + i×2^1 = 22 (base of operations 10)
Conversion from Decimal (Base x) to Base r
Utilize repeated division/remainder. For instance,
To convert 261(base 10) to hexadecimal: 261/xvi => caliber=16 residue=five 16/xvi => quotient=1 remainder=0 1/sixteen => quotient=0 remainder=i (caliber=0 finish) Hence, 261D = 105H (Collect the hex digits from the remainder in opposite order)
The above process is actually applicative to conversion between any ii base systems. For example,
To convert 1023(base four) to base of operations 3: 1023(base of operations 4)/3 => quotient=25D rest=0 25D/three => caliber=8D remainder=one 8D/3 => quotient=second remainder=two 2d/3 => quotient=0 residual=2 (quotient=0 cease) Hence, 1023(base 4) = 2210(base three)
Conversion between Two Number Systems with Fractional Role
- Split up the integral and the fractional parts.
- For the integral office, divide by the target radix repeatably, and collect the ramainder in opposite society.
- For the fractional part, multiply the fractional office by the target radix repeatably, and collect the integral part in the same order.
Example 1: Decimal to Binary
Convert 18.6875D to binary Integral Part = 18D 18/2 => quotient=9 residual=0 9/ii => caliber=iv remainder=1 4/2 => caliber=ii balance=0 2/2 => quotient=ane remainder=0 1/2 => quotient=0 remainder=1 (quotient=0 finish) Hence, 18D = 10010B Partial Part = .6875D .6875*ii=i.375 => whole number is 1 .375*ii=0.75 => whole number is 0 .75*2=ane.v => whole number is one .v*ii=i.0 => whole number is 1 Hence .6875D = .1011B Combine, 18.6875D = 10010.1011B
Instance 2: Decimal to Hexadecimal
Convert 18.6875D to hexadecimal Integral Part = 18D 18/16 => quotient=one remainder=2 1/sixteen => quotient=0 remainder=1 (caliber=0 stop) Hence, 18D = 12H Fractional Function = .6875D .6875*16=eleven.0 => whole number is 11D (BH) Hence .6875D = .BH Combine, 18.6875D = 12.BH
Exercises (Number Systems Conversion)
- Convert the following decimal numbers into binary and hexadecimal numbers:
-
108 -
4848 -
9000
-
- Convert the post-obit binary numbers into hexadecimal and decimal numbers:
-
1000011000 -
10000000 -
101010101010
-
- Catechumen the post-obit hexadecimal numbers into binary and decimal numbers:
-
ABCDE -
1234 -
80F
-
- Convert the following decimal numbers into binary equivalent:
-
19.25D -
123.456D
-
Answers: You could use the Windows' Reckoner (calc.exe) to carry out number system conversion, by setting information technology to the Developer or scientific mode. (Run "calc" ⇒ Select "Settings" card ⇒ Cull "Programmer" or "Scientific" style.)
-
1101100B,1001011110000B,10001100101000B,6CH,12F0H,2328H. -
218H,80H,AAAH,536D,128D,2730D. -
10101011110011011110B,1001000110100B,100000001111B,703710D,4660D,2063D. - ?? (Yous piece of work it out!)
Computer Memory & Data Representation
Computer uses a fixed number of $.25 to represent a piece of data, which could be a number, a character, or others. A northward-bit storage location can represent up to 2^n distinct entities. For case, a 3-flake memory location tin concord one of these eight binary patterns: 000, 001, 010, 011, 100, 101, 110, or 111. Hence, it tin represent at most 8 singled-out entities. Y'all could use them to represent numbers 0 to 7, numbers 8881 to 8888, characters 'A' to 'H', or upwardly to eight kinds of fruits like apple, orangish, banana; or upwards to 8 kinds of animals like lion, tiger, etc.
Integers, for instance, can be represented in 8-bit, sixteen-bit, 32-flake or 64-chip. You, every bit the programmer, choose an advisable bit-length for your integers. Your choice will impose constraint on the range of integers that can be represented. Besides the bit-length, an integer can exist represented in various representation schemes, eastward.one thousand., unsigned vs. signed integers. An 8-bit unsigned integer has a range of 0 to 255, while an viii-bit signed integer has a range of -128 to 127 - both representing 256 distinct numbers.
It is of import to note that a estimator memory location merely stores a binary blueprint. It is entirely up to you, every bit the programmer, to decide on how these patterns are to be interpreted. For example, the 8-bit binary pattern "0100 0001B" can be interpreted as an unsigned integer 65, or an ASCII character 'A', or some surreptitious information known just to you. In other words, y'all have to beginning decide how to stand for a piece of data in a binary pattern before the binary patterns make sense. The estimation of binary pattern is called data representation or encoding. Furthermore, it is important that the data representation schemes are agreed-upon past all the parties, i.due east., industrial standards need to be formulated and straightly followed.
Once you decided on the information representation scheme, sure constraints, in detail, the precision and range volition be imposed. Hence, information technology is important to understand data representation to write right and high-performance programs.
Rosette Stone and the Decipherment of Egyptian Hieroglyphs


Egyptian hieroglyphs (adjacent-to-left) were used by the ancient Egyptians since 4000BC. Unfortunately, since 500AD, no one could longer read the ancient Egyptian hieroglyphs, until the re-discovery of the Rosette Stone in 1799 past Napoleon's troop (during Napoleon's Egyptian invasion) almost the boondocks of Rashid (Rosetta) in the Nile Delta.
The Rosetta Stone (left) is inscribed with a decree in 196BC on behalf of Rex Ptolemy V. The decree appears in three scripts: the upper text is Ancient Egyptian hieroglyphs, the middle portion Demotic script, and the lowest Ancient Greek. Considering information technology presents substantially the same text in all three scripts, and Ancient Greek could still exist understood, it provided the central to the decipherment of the Egyptian hieroglyphs.
The moral of the story is unless you know the encoding scheme, there is no mode that you lot tin can decode the information.
Reference and images: Wikipedia.
Integer Representation
Integers are whole numbers or fixed-point numbers with the radix point stock-still after the least-meaning bit. They are dissimilarity to real numbers or floating-indicate numbers, where the position of the radix point varies. It is important to take note that integers and floating-point numbers are treated differently in computers. They have different representation and are processed differently (e.grand., floating-point numbers are processed in a so-called floating-point processor). Floating-bespeak numbers will be discussed later.
Computers use a fixed number of bits to correspond an integer. The commonly-used flake-lengths for integers are 8-bit, 16-chip, 32-scrap or 64-bit. Besides bit-lengths, there are 2 representation schemes for integers:
- Unsigned Integers: can represent zippo and positive integers.
- Signed Integers: can represent nix, positive and negative integers. Three representation schemes had been proposed for signed integers:
- Sign-Magnitude representation
- 1's Complement representation
- 2'south Complement representation
You, as the programmer, need to determine on the bit-length and representation scheme for your integers, depending on your application's requirements. Suppose that y'all need a counter for counting a pocket-size quantity from 0 up to 200, you might choose the eight-scrap unsigned integer scheme equally there is no negative numbers involved.
n-bit Unsigned Integers
Unsigned integers tin can represent zero and positive integers, but not negative integers. The value of an unsigned integer is interpreted as "the magnitude of its underlying binary blueprint".
Example 1: Suppose that n=viii and the binary pattern is 0100 0001B, the value of this unsigned integer is 1×2^0 + 1×2^six = 65D.
Example 2: Suppose that n=16 and the binary pattern is 0001 0000 0000 1000B, the value of this unsigned integer is i×two^3 + 1×2^12 = 4104D.
Example three: Suppose that n=sixteen and the binary pattern is 0000 0000 0000 0000B, the value of this unsigned integer is 0.
An n-bit pattern can represent 2^n distinct integers. An north-bit unsigned integer tin can represent integers from 0 to (ii^n)-1, as tabulated below:
| due north | Minimum | Maximum |
|---|---|---|
| 8 | 0 | (2^8)-ane (=255) |
| 16 | 0 | (2^xvi)-1 (=65,535) |
| 32 | 0 | (2^32)-1 (=four,294,967,295) (9+ digits) |
| 64 | 0 | (two^64)-i (=18,446,744,073,709,551,615) (19+ digits) |
Signed Integers
Signed integers can represent zero, positive integers, as well as negative integers. Three representation schemes are available for signed integers:
- Sign-Magnitude representation
- 1's Complement representation
- 2'southward Complement representation
In all the above three schemes, the most-pregnant flake (msb) is chosen the sign flake. The sign bit is used to correspond the sign of the integer - with 0 for positive integers and ane for negative integers. The magnitude of the integer, however, is interpreted differently in dissimilar schemes.
north-bit Sign Integers in Sign-Magnitude Representation
In sign-magnitude representation:
- The almost-significant scrap (msb) is the sign bit, with value of 0 representing positive integer and 1 representing negative integer.
- The remaining due north-1 $.25 represents the magnitude (accented value) of the integer. The absolute value of the integer is interpreted every bit "the magnitude of the (northward-1)-chip binary pattern".
Example ane: Suppose that n=8 and the binary representation is 0 100 0001B.
Sign bit is 0 ⇒ positive
Absolute value is 100 0001B = 65D
Hence, the integer is +65D
Example 2: Suppose that north=8 and the binary representation is 1 000 0001B.
Sign bit is i ⇒ negative
Absolute value is 000 0001B = 1D
Hence, the integer is -1D
Example iii: Suppose that n=eight and the binary representation is 0 000 0000B.
Sign bit is 0 ⇒ positive
Accented value is 000 0000B = 0D
Hence, the integer is +0D
Example 4: Suppose that n=8 and the binary representation is 1 000 0000B.
Sign bit is ane ⇒ negative
Absolute value is 000 0000B = 0D
Hence, the integer is -0D
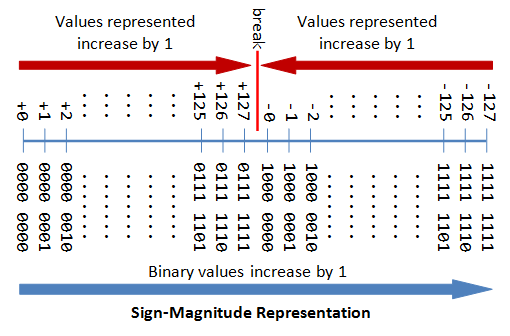
The drawbacks of sign-magnitude representation are:
- There are ii representations (
0000 0000Bandone thousand 0000B) for the number zero, which could lead to inefficiency and confusion. - Positive and negative integers need to be processed separately.
n-bit Sign Integers in 1's Complement Representation
In 1's complement representation:
- Again, the most meaning bit (msb) is the sign scrap, with value of 0 representing positive integers and i representing negative integers.
- The remaining n-ane bits represents the magnitude of the integer, as follows:
- for positive integers, the absolute value of the integer is equal to "the magnitude of the (due north-1)-flake binary pattern".
- for negative integers, the absolute value of the integer is equal to "the magnitude of the complement (inverse) of the (n-1)-bit binary pattern" (hence called 1's complement).
Example i: Suppose that n=8 and the binary representation 0 100 0001B.
Sign bit is 0 ⇒ positive
Accented value is 100 0001B = 65D
Hence, the integer is +65D
Case 2: Suppose that n=8 and the binary representation ane 000 0001B.
Sign flake is 1 ⇒ negative
Absolute value is the complement of 000 0001B, i.e., 111 1110B = 126D
Hence, the integer is -126D
Example 3: Suppose that n=eight and the binary representation 0 000 0000B.
Sign bit is 0 ⇒ positive
Accented value is 000 0000B = 0D
Hence, the integer is +0D
Example iv: Suppose that n=8 and the binary representation 1 111 1111B.
Sign bit is i ⇒ negative
Absolute value is the complement of 111 1111B, i.e., 000 0000B = 0D
Hence, the integer is -0D
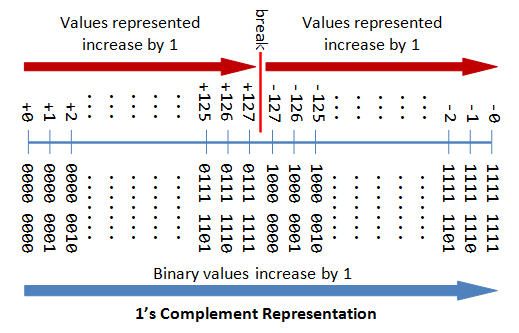
Again, the drawbacks are:
- At that place are two representations (
0000 0000Band1111 1111B) for zero. - The positive integers and negative integers need to be candy separately.
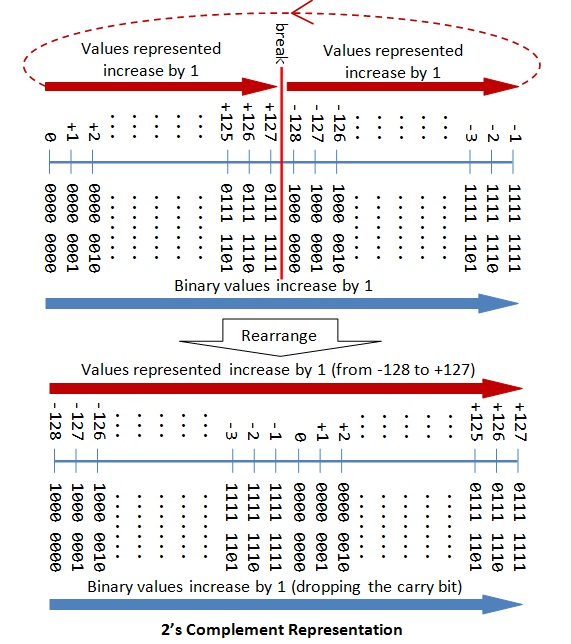
n-bit Sign Integers in 2's Complement Representation
In ii'south complement representation:
- Once again, the about significant scrap (msb) is the sign bit, with value of 0 representing positive integers and one representing negative integers.
- The remaining northward-1 $.25 represents the magnitude of the integer, as follows:
- for positive integers, the accented value of the integer is equal to "the magnitude of the (n-1)-bit binary pattern".
- for negative integers, the absolute value of the integer is equal to "the magnitude of the complement of the (northward-1)-flake binary pattern plus 1" (hence called 2's complement).
Instance ane: Suppose that n=eight and the binary representation 0 100 0001B.
Sign bit is 0 ⇒ positive
Accented value is 100 0001B = 65D
Hence, the integer is +65D
Example 2: Suppose that n=8 and the binary representation 1 000 0001B.
Sign bit is ane ⇒ negative
Absolute value is the complement of 000 0001B plus one, i.eastward., 111 1110B + 1B = 127D
Hence, the integer is -127D
Case three: Suppose that north=8 and the binary representation 0 000 0000B.
Sign bit is 0 ⇒ positive
Accented value is 000 0000B = 0D
Hence, the integer is +0D
Example four: Suppose that n=viii and the binary representation 1 111 1111B.
Sign fleck is one ⇒ negative
Accented value is the complement of 111 1111B plus i, i.e., 000 0000B + 1B = 1D
Hence, the integer is -1D
Computers use two's Complement Representation for Signed Integers
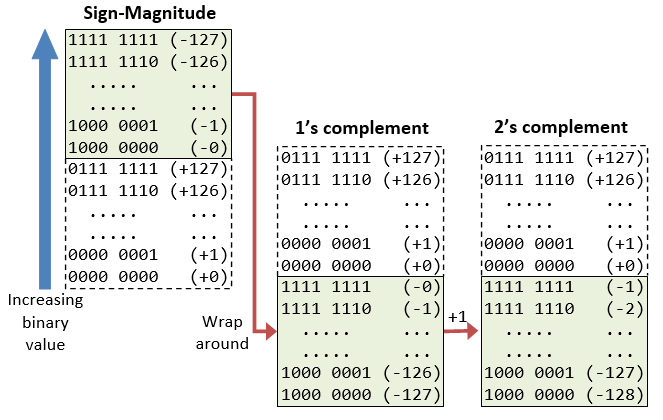
We have discussed three representations for signed integers: signed-magnitude, ane's complement and 2's complement. Computers use 2'south complement in representing signed integers. This is because:
- There is only one representation for the number zero in 2's complement, instead of two representations in sign-magnitude and ane'south complement.
- Positive and negative integers can be treated together in addition and subtraction. Subtraction can exist carried out using the "add-on logic".
Case 1: Addition of Two Positive Integers: Suppose that n=8, 65D + 5D = 70D
65D → 0100 0001B 5D → 0000 0101B(+ 0100 0110B → 70D (OK)
Example 2: Subtraction is treated as Addition of a Positive and a Negative Integers: Suppose that n=8, 5D - 5D = 65D + (-5D) = 60D
65D → 0100 0001B -5D → 1111 1011B(+ 0011 1100B → 60D (discard carry - OK)
Example 3: Add-on of Two Negative Integers: Suppose that n=viii, -65D - 5D = (-65D) + (-5D) = -70D
-65D → 1011 1111B -5D → 1111 1011B(+ 1011 1010B → -70D (discard carry - OK)
Because of the fixed precision (i.e., stock-still number of bits), an north-bit 2's complement signed integer has a certain range. For case, for n=viii, the range of two's complement signed integers is -128 to +127. During improver (and subtraction), it is important to check whether the upshot exceeds this range, in other words, whether overflow or underflow has occurred.
Case 4: Overflow: Suppose that northward=8, 127D + 2d = 129D (overflow - beyond the range)
127D → 0111 1111B 2D → 0000 0010B(+ 1000 0001B → -127D (incorrect)
Example v: Underflow: Suppose that n=viii, -125D - 5D = -130D (underflow - below the range)
-125D → grand 0011B -5D → 1111 1011B(+ 0111 1110B → +126D (wrong)
The post-obit diagram explains how the 2's complement works. By re-arranging the number line, values from -128 to +127 are represented contiguously by ignoring the bear fleck.
Range of n-bit 2'southward Complement Signed Integers
An n-bit 2'south complement signed integer can represent integers from -two^(n-i) to +2^(n-1)-1, as tabulated. Take note that the scheme can correspond all the integers inside the range, without whatsoever gap. In other words, there is no missing integers within the supported range.
| n | minimum | maximum |
|---|---|---|
| 8 | -(2^7) (=-128) | +(2^7)-ane (=+127) |
| sixteen | -(2^15) (=-32,768) | +(2^xv)-1 (=+32,767) |
| 32 | -(two^31) (=-2,147,483,648) | +(ii^31)-ane (=+2,147,483,647)(nine+ digits) |
| 64 | -(2^63) (=-9,223,372,036,854,775,808) | +(ii^63)-1 (=+9,223,372,036,854,775,807)(18+ digits) |
Decoding ii's Complement Numbers
- Cheque the sign bit (denoted as
S). - If
S=0, the number is positive and its absolute value is the binary value of the remaining n-one bits. - If
S=1, the number is negative. yous could "capsize the north-1 $.25 and plus 1" to get the absolute value of negative number.
Alternatively, you could browse the remaining due north-one bits from the right (least-meaning bit). Look for the first occurrence of 1. Flip all the bits to the left of that commencement occurrence of 1. The flipped pattern gives the accented value. For example,n = 8, bit pattern = 1 100 0100B Southward = 1 → negative Scanning from the right and flip all the bits to the left of the offset occurrence of 1 ⇒ 011 ane100B = 60D Hence, the value is -60D
Large Endian vs. Little Endian
Modernistic computers store one byte of information in each retention address or location, i.e., byte addressable retentivity. An 32-bit integer is, therefore, stored in 4 memory addresses.
The term"Endian" refers to the order of storing bytes in calculator retention. In "Big Endian" scheme, the most meaning byte is stored first in the lowest memory address (or big in get-go), while "Little Endian" stores the least significant bytes in the lowest retentiveness address.
For example, the 32-scrap integer 12345678H (30541989610) is stored equally 12H 34H 56H 78H in big endian; and 78H 56H 34H 12H in little endian. An 16-fleck integer 00H 01H is interpreted equally 0001H in big endian, and 0100H as footling endian.
Exercise (Integer Representation)
- What are the ranges of 8-bit, 16-bit, 32-bit and 64-bit integer, in "unsigned" and "signed" representation?
- Give the value of
88,0,one,127, and255in - Give the value of
+88,-88,-1,0,+one,-128, and+127in 8-bit 2'south complement signed representation. - Give the value of
+88,-88,-1,0,+one,-127, and+127in 8-chip sign-magnitude representation. - Give the value of
+88,-88,-1,0,+i,-127and+127in 8-scrap i'south complement representation. - [TODO] more than.
Answers
- The range of unsigned n-fleck integers is
[0, 2^n - one]. The range of n-bit ii's complement signed integer is[-2^(n-1), +2^(n-ane)-1]; -
88 (0101 1000),0 (0000 0000),ane (0000 0001),127 (0111 1111),255 (1111 1111). -
+88 (0101 k),-88 (1010 1000),-1 (1111 1111),0 (0000 0000),+1 (0000 0001),-128 (k 0000),+127 (0111 1111). -
+88 (0101 1000),-88 (1101 1000),-1 (one thousand 0001),0 (0000 0000 or 1000 0000),+1 (0000 0001),-127 (1111 1111),+127 (0111 1111). -
+88 (0101 1000),-88 (1010 0111),-1 (1111 1110),0 (0000 0000 or 1111 1111),+one (0000 0001),-127 (k 0000),+127 (0111 1111).
Floating-Point Number Representation
A floating-bespeak number (or real number) can represent a very large (1.23×x^88) or a very small (1.23×ten^-88) value. It could besides represent very large negative number (-1.23×10^88) and very small negative number (-one.23×10^88), equally well as zero, as illustrated:
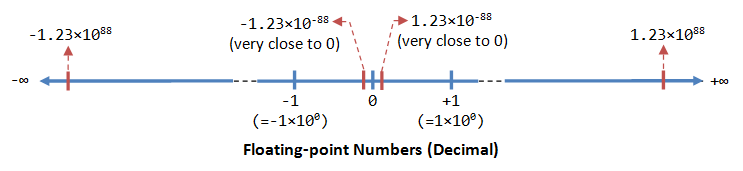
A floating-bespeak number is typically expressed in the scientific notation, with a fraction (F), and an exponent (Eastward) of a certain radix (r), in the form of F×r^E. Decimal numbers utilise radix of 10 (F×10^Due east); while binary numbers use radix of ii (F×two^East).
Representation of floating point number is not unique. For example, the number 55.66 can be represented as 5.566×10^1, 0.5566×x^two, 0.05566×10^3, and so on. The fractional role can exist normalized. In the normalized course, in that location is only a unmarried non-goose egg digit before the radix indicate. For example, decimal number 123.4567 can be normalized every bit 1.234567×ten^ii; binary number 1010.1011B can be normalized as 1.0101011B×ii^3.
It is important to note that floating-signal numbers suffer from loss of precision when represented with a fixed number of bits (due east.g., 32-bit or 64-bit). This is because there are infinite number of real numbers (even within a small range of says 0.0 to 0.1). On the other hand, a n-bit binary blueprint tin represent a finite two^due north singled-out numbers. Hence, not all the real numbers can be represented. The nearest approximation will be used instead, resulted in loss of accuracy.
Information technology is besides of import to annotation that floating number arithmetic is very much less efficient than integer arithmetic. It could be speed upwardly with a so-called dedicated floating-point co-processor. Hence, use integers if your awarding does non require floating-bespeak numbers.
In computers, floating-indicate numbers are represented in scientific notation of fraction (F) and exponent (E) with a radix of ii, in the course of F×ii^E. Both Eastward and F can exist positive too as negative. Modernistic computers adopt IEEE 754 standard for representing floating-signal numbers. At that place are two representation schemes: 32-bit single-precision and 64-flake double-precision.
IEEE-754 32-flake Unmarried-Precision Floating-Point Numbers
In 32-fleck unmarried-precision floating-point representation:
- The most significant bit is the sign bit (
S), with 0 for positive numbers and i for negative numbers. - The post-obit 8 bits represent exponent (
E). - The remaining 23 bits represents fraction (
F).
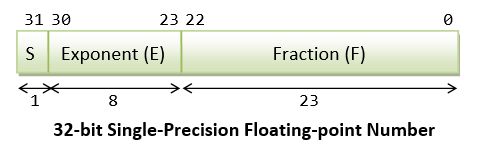
Normalized Form
Let'south illustrate with an example, suppose that the 32-bit blueprint is one 1000 0001 011 0000 0000 0000 0000 0000 , with:
-
S = i -
E = 1000 0001 -
F = 011 0000 0000 0000 0000 0000
In the normalized form, the actual fraction is normalized with an implicit leading one in the grade of ane.F. In this instance, the actual fraction is 1.011 0000 0000 0000 0000 0000 = 1 + 1×2^-two + 1×2^-3 = ane.375D.
The sign bit represents the sign of the number, with S=0 for positive and S=1 for negative number. In this example with South=1, this is a negative number, i.e., -i.375D.
In normalized form, the actual exponent is East-127 (so-called excess-127 or bias-127). This is because we need to represent both positive and negative exponent. With an 8-bit E, ranging from 0 to 255, the excess-127 scheme could provide bodily exponent of -127 to 128. In this case, E-127=129-127=2d.
Hence, the number represented is -1.375×ii^ii=-5.5D.
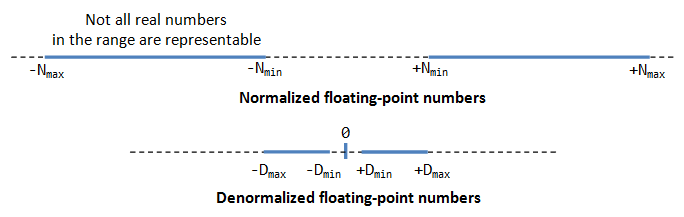
De-Normalized Form
Normalized course has a serious problem, with an implicit leading one for the fraction, it cannot represent the number zero! Convince yourself on this!
De-normalized form was devised to correspond cipher and other numbers.
For Eastward=0, the numbers are in the de-normalized grade. An implicit leading 0 (instead of 1) is used for the fraction; and the actual exponent is always -126. Hence, the number cipher can be represented with E=0 and F=0 (because 0.0×2^-126=0).
Nosotros tin can likewise stand for very modest positive and negative numbers in de-normalized grade with East=0. For example, if S=1, E=0, and F=011 0000 0000 0000 0000 0000. The actual fraction is 0.011=i×2^-2+i×ii^-3=0.375D. Since S=1, information technology is a negative number. With E=0, the actual exponent is -126. Hence the number is -0.375×2^-126 = -four.4×ten^-39, which is an extremely small negative number (close to cipher).
Summary
In summary, the value (N) is calculated as follows:
- For
1 ≤ E ≤ 254, N = (-1)^South × 1.F × two^(E-127). These numbers are in the and so-called normalized form. The sign-bit represents the sign of the number. Fractional part (1.F) are normalized with an implicit leading 1. The exponent is bias (or in backlog) of127, so as to represent both positive and negative exponent. The range of exponent is-126to+127. - For
Eastward = 0, N = (-ane)^S × 0.F × 2^(-126). These numbers are in the so-chosen denormalized class. The exponent of2^-126evaluates to a very pocket-size number. Denormalized form is needed to correspond zero (withF=0andE=0). It can also represents very small positive and negative number shut to zip. - For
E = 255, it represents special values, such equally±INF(positive and negative infinity) andNaN(non a number). This is beyond the scope of this commodity.
Instance 1: Suppose that IEEE-754 32-fleck floating-signal representation blueprint is 0 10000000 110 0000 0000 0000 0000 0000 .
Sign fleck S = 0 ⇒ positive number East = 1000 0000B = 128D (in normalized form) Fraction is 1.11B (with an implicit leading 1) = 1 + 1×2^-1 + 1×two^-2 = 1.75D The number is +1.75 × ii^(128-127) = +iii.5D
Example 2: Suppose that IEEE-754 32-fleck floating-point representation pattern is 1 01111110 100 0000 0000 0000 0000 0000 .
Sign scrap S = 1 ⇒ negative number E = 0111 1110B = 126D (in normalized grade) Fraction is one.1B (with an implicit leading i) = 1 + 2^-one = ane.5D The number is -1.v × two^(126-127) = -0.75D
Case 3: Suppose that IEEE-754 32-bit floating-point representation pattern is 1 01111110 000 0000 0000 0000 0000 0001 .
Sign bit S = 1 ⇒ negative number Eastward = 0111 1110B = 126D (in normalized form) Fraction is 1.000 0000 0000 0000 0000 0001B (with an implicit leading i) = 1 + 2^-23 The number is -(1 + 2^-23) × two^(126-127) = -0.500000059604644775390625 (may non exist exact in decimal!)
Example 4 (De-Normalized Form): Suppose that IEEE-754 32-bit floating-point representation pattern is ane 00000000 000 0000 0000 0000 0000 0001 .
Sign chip S = ane ⇒ negative number E = 0 (in de-normalized form) Fraction is 0.000 0000 0000 0000 0000 0001B (with an implicit leading 0) = 1×ii^-23 The number is -two^-23 × two^(-126) = -ii×(-149) ≈ -one.four×x^-45
Exercises (Floating-betoken Numbers)
- Compute the largest and smallest positive numbers that can be represented in the 32-bit normalized form.
- Compute the largest and smallest negative numbers can exist represented in the 32-bit normalized form.
- Repeat (1) for the 32-chip denormalized form.
- Echo (2) for the 32-bit denormalized form.
Hints:
- Largest positive number:
Due south=0,E=1111 1110 (254),F=111 1111 1111 1111 1111 1111.
Smallest positive number:S=0,Eastward=0000 00001 (ane),F=000 0000 0000 0000 0000 0000. - Aforementioned equally to a higher place, but
Southward=1. - Largest positive number:
South=0,E=0,F=111 1111 1111 1111 1111 1111.
Smallest positive number:S=0,E=0,F=000 0000 0000 0000 0000 0001. - Aforementioned as above, but
Due south=1.
Notes For Coffee Users
You can utilize JDK methods Float.intBitsToFloat(int bits) or Double.longBitsToDouble(long bits) to create a single-precision 32-scrap float or double-precision 64-scrap double with the specific bit patterns, and print their values. For examples,
System.out.println(Float.intBitsToFloat(0x7fffff)); System.out.println(Double.longBitsToDouble(0x1fffffffffffffL));
IEEE-754 64-bit Double-Precision Floating-Betoken Numbers
The representation scheme for 64-bit double-precision is similar to the 32-fleck single-precision:
- The nigh significant bit is the sign chip (
South), with 0 for positive numbers and 1 for negative numbers. - The following 11 bits stand for exponent (
Due east). - The remaining 52 bits represents fraction (
F).

The value (N) is calculated as follows:
- Normalized form: For
i ≤ E ≤ 2046, North = (-ane)^S × 1.F × 2^(E-1023). - Denormalized form: For
E = 0, Northward = (-i)^S × 0.F × 2^(-1022). These are in the denormalized form. - For
E = 2047,Northrepresents special values, such as±INF(infinity),NaN(not a number).
More than on Floating-Point Representation
There are three parts in the floating-point representation:
- The sign bit (
S) is self-explanatory (0 for positive numbers and 1 for negative numbers). - For the exponent (
E), a and so-called bias (or excess) is applied and then as to represent both positive and negative exponent. The bias is set at half of the range. For single precision with an 8-bit exponent, the bias is 127 (or excess-127). For double precision with a xi-bit exponent, the bias is 1023 (or excess-1023). - The fraction (
F) (also called the mantissa or significand) is composed of an implicit leading bit (before the radix bespeak) and the fractional bits (after the radix point). The leading bit for normalized numbers is one; while the leading fleck for denormalized numbers is 0.
Normalized Floating-Indicate Numbers
In normalized form, the radix point is placed after the first non-nil digit, e,thou., nine.8765D×10^-23D, ane.001011B×two^11B. For binary number, the leading scrap is always 1, and need not exist represented explicitly - this saves 1 bit of storage.
In IEEE 754'due south normalized grade:
- For unmarried-precision,
1 ≤ Due east ≤ 254with excess of 127. Hence, the actual exponent is from-126to+127. Negative exponents are used to correspond small numbers (< i.0); while positive exponents are used to represent big numbers (> 1.0).Due north = (-i)^Southward × 1.F × 2^(E-127) - For double-precision,
ane ≤ E ≤ 2046with excess of 1023. The actual exponent is from-1022to+1023, andNorth = (-1)^S × i.F × 2^(E-1023)
Accept notation that due north-flake design has a finite number of combinations (=2^n), which could correspond finite distinct numbers. It is non possible to stand for the space numbers in the real axis (even a minor range says 0.0 to 1.0 has space numbers). That is, not all floating-point numbers can be accurately represented. Instead, the closest approximation is used, which leads to loss of accurateness.
The minimum and maximum normalized floating-point numbers are:
| Precision | Normalized N(min) | Normalized Due north(max) |
|---|---|---|
| Unmarried | 0080 0000H 0 00000001 00000000000000000000000B E = 1, F = 0 North(min) = one.0B × 2^-126 (≈i.17549435 × 10^-38) | 7F7F FFFFH 0 11111110 00000000000000000000000B E = 254, F = 0 N(max) = 1.1...1B × 2^127 = (2 - 2^-23) × two^127 (≈iii.4028235 × 10^38) |
| Double | 0010 0000 0000 0000H Due north(min) = 1.0B × 2^-1022 (≈2.2250738585072014 × 10^-308) | 7FEF FFFF FFFF FFFFH N(max) = 1.i...1B × 2^1023 = (2 - 2^-52) × 2^1023 (≈i.7976931348623157 × 10^308) |
Denormalized Floating-Point Numbers
If E = 0, but the fraction is non-zero, then the value is in denormalized form, and a leading scrap of 0 is causeless, as follows:
- For single-precision,
E = 0,N = (-i)^S × 0.F × 2^(-126) - For double-precision,
E = 0,N = (-1)^Due south × 0.F × 2^(-1022)
Denormalized class can stand for very small numbers closed to zero, and zippo, which cannot exist represented in normalized form, as shown in the to a higher place effigy.
The minimum and maximum of denormalized floating-point numbers are:
| Precision | Denormalized D(min) | Denormalized D(max) |
|---|---|---|
| Unmarried | 0000 0001H 0 00000000 00000000000000000000001B E = 0, F = 00000000000000000000001B D(min) = 0.0...i × 2^-126 = 1 × two^-23 × two^-126 = two^-149 (≈1.iv × 10^-45) | 007F FFFFH 0 00000000 11111111111111111111111B E = 0, F = 11111111111111111111111B D(max) = 0.1...1 × 2^-126 = (one-2^-23)×2^-126 (≈1.1754942 × 10^-38) |
| Double | 0000 0000 0000 0001H D(min) = 0.0...1 × 2^-1022 = 1 × 2^-52 × 2^-1022 = 2^-1074 (≈4.9 × 10^-324) | 001F FFFF FFFF FFFFH D(max) = 0.1...1 × 2^-1022 = (1-2^-52)×2^-1022 (≈4.4501477170144023 × 10^-308) |
Special Values
Zero: Zero cannot exist represented in the normalized form, and must be represented in denormalized form with E=0 and F=0. There are two representations for nil: +0 with S=0 and -0 with S=1.
Infinity: The value of +infinity (e.m., 1/0) and -infinity (east.thousand., -1/0) are represented with an exponent of all 1's (E = 255 for unmarried-precision and E = 2047 for double-precision), F=0, and South=0 (for +INF) and Southward=1 (for -INF).
Non a Number (NaN): NaN denotes a value that cannot be represented every bit real number (e.grand. 0/0). NaN is represented with Exponent of all one's (E = 255 for single-precision and E = 2047 for double-precision) and any non-zilch fraction.
Character Encoding
In estimator memory, character are "encoded" (or "represented") using a called "grapheme encoding schemes" (aka "grapheme set", "charset", "character map", or "code folio").
For example, in ASCII (also every bit Latin1, Unicode, and many other graphic symbol sets):
- code numbers
65D (41H)to90D (5AH)represents'A'to'Z', respectively. - code numbers
97D (61H)to122D (7AH)represents'a'to'z', respectively. - lawmaking numbers
48D (30H)to57D (39H)represents'0'to'9', respectively.
Information technology is of import to note that the representation scheme must exist known before a binary blueprint can be interpreted. Eastward.one thousand., the 8-flake blueprint "0100 0010B" could represent anything under the sun known merely to the person encoded it.
The nigh commonly-used character encoding schemes are: vii-bit ASCII (ISO/IEC 646) and 8-bit Latin-x (ISO/IEC 8859-x) for western european characters, and Unicode (ISO/IEC 10646) for internationalization (i18n).
A 7-bit encoding scheme (such equally ASCII) can stand for 128 characters and symbols. An 8-bit character encoding scheme (such as Latin-10) can represent 256 characters and symbols; whereas a 16-bit encoding scheme (such as Unicode UCS-2) can represents 65,536 characters and symbols.
7-bit ASCII Code (aka US-ASCII, ISO/IEC 646, ITU-T T.50)
- ASCII (American Standard Code for Information Interchange) is ane of the before character coding schemes.
- ASCII is originally a 7-bit code. It has been extended to viii-bit to better utilize the 8-bit computer retentivity organization. (The 8th-bit was originally used for parity check in the early computers.)
- Code numbers
32D (20H)to126D (7EH)are printable (displayable) characters as tabulated (arranged in hexadecimal and decimal) as follows:Hex 0 1 two 3 four 5 6 7 8 ix A B C D E F 2 SP ! " # $ % & ' ( ) * + , - . / 3 0 i 2 3 iv five 6 7 8 9 : ; < = > ? 4 @ A B C D Due east F Grand H I J Chiliad L 1000 Due north O five P Q R S T U Five W Ten Y Z [ \ ] ^ _ vi ` a b c d e f k h i j k fifty m n o 7 p q r s t u v w 10 y z { | } ~
Dec 0 1 ii 3 four five 6 7 8 9 3 SP ! " # $ % & ' 4 ( ) * + , - . / 0 1 v 2 3 4 5 half dozen 7 8 nine : ; half dozen < = > ? @ A B C D E 7 F G H I J K L Chiliad N O 8 P Q R S T U V W X Y 9 Z [ \ ] ^ _ ` a b c x d e f thousand h i j k l m xi north o p q r south t u v w 12 x y z { | } ~ - Code number
32D (20H)is the blank or space character. -
'0'to'9':30H-39H (0011 0001B to 0011 1001B)or(0011 xxxxBwherexxxxis the equivalent integer value) -
'A'to'Z':41H-5AH (0101 0001B to 0101 1010B)or(010x xxxxB).'A'to'Z'are continuous without gap. -
'a'to'z':61H-7AH (0110 0001B to 0111 1010B)or(011x xxxxB).'A'to'Z'are also continuous without gap. However, in that location is a gap between uppercase and lowercase letters. To convert between upper and lowercase, flip the value of fleck-5.
- Code number
- Code numbers
0D (00H)to31D (1FH), and127D (7FH)are special control characters, which are not-printable (non-displayable), as tabulated below. Many of these characters were used in the early days for manual control (due east.g., STX, ETX) and printer control (due east.g., Grade-Feed), which are now obsolete. The remaining meaningful codes today are:-
09Hfor Tab ('\t'). -
0AHfor Line-Feed or newline (LF or'\n') and0DHfor Carriage-Render (CR or'r'), which are used as line delimiter (aka line separator, cease-of-line) for text files. There is unfortunately no standard for line delimiter: Unixes and Mac utilise0AH(LF or "\n"), Windows utilize0D0AH(CR+LF or "\r\due north"). Programming languages such as C/C++/Java (which was created on Unix) use0AH(LF or "\n"). - In programming languages such as C/C++/Coffee, line-feed (
0AH) is denoted as'\n', carriage-return (0DH) equally'\r', tab (09H) equally'\t'.
-
| December | HEX | Meaning | DEC | HEX | Meaning | ||
|---|---|---|---|---|---|---|---|
| 0 | 00 | NUL | Null | 17 | 11 | DC1 | Device Control 1 |
| 1 | 01 | SOH | Start of Heading | 18 | 12 | DC2 | Device Control 2 |
| 2 | 02 | STX | Kickoff of Text | 19 | 13 | DC3 | Device Control 3 |
| 3 | 03 | ETX | End of Text | 20 | 14 | DC4 | Device Control 4 |
| 4 | 04 | EOT | Stop of Transmission | 21 | fifteen | NAK | Negative Ack. |
| 5 | 05 | ENQ | Enquiry | 22 | 16 | SYN | Sync. Idle |
| 6 | 06 | ACK | Acquittance | 23 | 17 | ETB | End of Transmission |
| vii | 07 | BEL | Bell | 24 | 18 | CAN | Cancel |
| 8 | 08 | BS | Back Space '\b' | 25 | 19 | EM | End of Medium |
| 9 | 09 | HT | Horizontal Tab '\t' | 26 | 1A | SUB | Substitute |
| 10 | 0A | LF | Line Feed '\northward' | 27 | 1B | ESC | Escape |
| 11 | 0B | VT | Vertical Feed | 28 | 1C | IS4 | File Separator |
| 12 | 0C | FF | Course Feed 'f' | 29 | 1D | IS3 | Group Separator |
| xiii | 0D | CR | Wagon Return '\r' | 30 | 1E | IS2 | Record Separator |
| 14 | 0E | SO | Shift Out | 31 | 1F | IS1 | Unit Separator |
| 15 | 0F | SI | Shift In | ||||
| 16 | 10 | DLE | Datalink Escape | 127 | 7F | DEL | Delete |
eight-bit Latin-1 (aka ISO/IEC 8859-ane)
ISO/IEC-8859 is a collection of viii-bit graphic symbol encoding standards for the western languages.
ISO/IEC 8859-1, aka Latin alphabet No. 1, or Latin-one in short, is the most ordinarily-used encoding scheme for western european languages. Information technology has 191 printable characters from the latin script, which covers languages like English language, German, Italian, Portuguese and Spanish. Latin-1 is backward compatible with the 7-flake Usa-ASCII code. That is, the commencement 128 characters in Latin-1 (lawmaking numbers 0 to 127 (7FH)), is the same equally United states of america-ASCII. Lawmaking numbers 128 (80H) to 159 (9FH) are not assigned. Code numbers 160 (A0H) to 255 (FFH) are given as follows:
| Hex | 0 | one | 2 | 3 | iv | 5 | 6 | 7 | 8 | nine | A | B | C | D | Eastward | F |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| A | NBSP | ¡ | ¢ | £ | ¤ | ¥ | ¦ | § | ¨ | © | ª | « | ¬ | SHY | ® | ¯ |
| B | ° | ± | ² | ³ | ´ | µ | ¶ | · | ¸ | ¹ | º | » | ¼ | ½ | ¾ | ¿ |
| C | À | Á | Â | Ã | Ä | Å | Æ | Ç | È | É | Ê | Ë | Ì | Í | Î | Ï |
| D | Ð | Ñ | Ò | Ó | Ô | Õ | Ö | × | Ø | Ù | Ú | Û | Ü | Ý | Þ | ß |
| E | à | á | â | ã | ä | å | æ | ç | è | é | ê | ë | ì | í | î | ï |
| F | ð | ñ | ò | ó | ô | õ | ö | ÷ | ø | ù | ú | û | ü | ý | þ | ÿ |
ISO/IEC-8859 has 16 parts. As well the well-nigh commonly-used Role 1, Part 2 is meant for Cardinal European (Smoothen, Czech, Hungarian, etc), Part 3 for Southward European (Turkish, etc), Part four for N European (Estonian, Latvian, etc), Part 5 for Cyrillic, Part six for Arabic, Part vii for Greek, Role 8 for Hebrew, Part 9 for Turkish, Part ten for Nordic, Role xi for Thai, Part 12 was abandon, Part thirteen for Baltic Rim, Role 14 for Celtic, Part 15 for French, Finnish, etc. Part xvi for South-Eastern European.
Other 8-flake Extension of US-ASCII (ASCII Extensions)
Beside the standardized ISO-8859-ten, at that place are many viii-bit ASCII extensions, which are non compatible with each others.
ANSI (American National Standards Constitute) (aka Windows-1252, or Windows Codepage 1252): for Latin alphabets used in the legacy DOS/Windows systems. Information technology is a superset of ISO-8859-1 with code numbers 128 (80H) to 159 (9FH) assigned to displayable characters, such equally "smart" single-quotes and double-quotes. A mutual trouble in web browsers is that all the quotes and apostrophes (produced by "smart quotes" in some Microsoft software) were replaced with question marks or some foreign symbols. It it because the document is labeled as ISO-8859-ane (instead of Windows-1252), where these code numbers are undefined. Most modern browsers and due east-mail clients care for charset ISO-8859-1 every bit Windows-1252 in order to adapt such mis-labeling.
| Hex | 0 | 1 | 2 | iii | 4 | 5 | vi | 7 | 8 | 9 | A | B | C | D | E | F |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 8 | € | ‚ | ƒ | „ | … | † | ‡ | ˆ | ‰ | Š | ‹ | Œ | Ž | |||
| nine | ' | ' | " | " | • | – | — | ™ | š | › | œ | ž | Ÿ |
EBCDIC (Extended Binary Coded Decimal Interchange Code): Used in the early IBM computers.
Unicode (aka ISO/IEC 10646 Universal Character Gear up)
Before Unicode, no single character encoding scheme could represent characters in all languages. For example, western european uses several encoding schemes (in the ISO-8859-x family unit). Even a unmarried linguistic communication like Chinese has a few encoding schemes (GB2312/GBK, BIG5). Many encoding schemes are in disharmonize of each other, i.due east., the same code number is assigned to different characters.
Unicode aims to provide a standard character encoding scheme, which is universal, efficient, uniform and unambiguous. Unicode standard is maintained by a non-turn a profit organization called the Unicode Consortium (@ www.unicode.org). Unicode is an ISO/IEC standard 10646.
Unicode is backward compatible with the 7-chip US-ASCII and eight-bit Latin-i (ISO-8859-1). That is, the first 128 characters are the same as U.s.-ASCII; and the start 256 characters are the same as Latin-1.
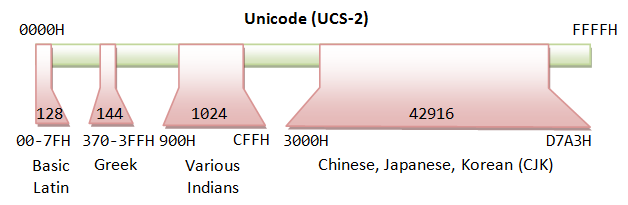
Unicode originally uses 16 bits (called UCS-2 or Unicode Character Ready - 2 byte), which tin represent up to 65,536 characters. It has since been expanded to more than 16 bits, currently stands at 21 bits. The range of the legal codes in ISO/IEC 10646 is at present from U+0000H to U+10FFFFH (21 bits or about 2 million characters), covering all electric current and ancient historical scripts. The original 16-chip range of U+0000H to U+FFFFH (65536 characters) is known as Basic Multilingual Plane (BMP), covering all the major languages in utilise currently. The characters outside BMP are chosen Supplementary Characters, which are non frequently-used.
Unicode has two encoding schemes:
- UCS-2 (Universal Graphic symbol Set - 2 Byte): Uses ii bytes (16 bits), covering 65,536 characters in the BMP. BMP is sufficient for almost of the applications. UCS-ii is now obsolete.
- UCS-4 (Universal Grapheme Prepare - 4 Byte): Uses 4 bytes (32 bits), covering BMP and the supplementary characters.
UTF-8 (Unicode Transformation Format - eight-chip)
The sixteen/32-bit Unicode (UCS-2/four) is grossly inefficient if the document contains mainly ASCII characters, because each character occupies two bytes of storage. Variable-length encoding schemes, such as UTF-8, which uses ane-4 bytes to represent a graphic symbol, was devised to better the efficiency. In UTF-8, the 128 commonly-used The states-ASCII characters use simply 1 byte, simply some less-commonly characters may crave up to iv bytes. Overall, the efficiency improved for document containing mainly The states-ASCII texts.
The transformation betwixt Unicode and UTF-8 is as follows:
| Bits | Unicode | UTF-8 Code | Bytes |
|---|---|---|---|
| 7 | 00000000 0xxxxxxx | 0xxxxxxx | one (ASCII) |
| eleven | 00000yyy yyxxxxxx | 110yyyyy 10xxxxxx | 2 |
| xvi | zzzzyyyy yyxxxxxx | 1110zzzz 10yyyyyy 10xxxxxx | 3 |
| 21 | 000uuuuu zzzzyyyy yyxxxxxx | 11110uuu 10uuzzzz 10yyyyyy 10xxxxxx | four |
In UTF-viii, Unicode numbers respective to the 7-bit ASCII characters are padded with a leading zippo; thus has the same value equally ASCII. Hence, UTF-eight tin can be used with all software using ASCII. Unicode numbers of 128 and to a higher place, which are less oftentimes used, are encoded using more bytes (2-4 bytes). UTF-viii generally requires less storage and is compatible with ASCII. The drawback of UTF-8 is more processing power needed to unpack the lawmaking due to its variable length. UTF-viii is the most pop format for Unicode.
Notes:
- UTF-viii uses one-3 bytes for the characters in BMP (16-flake), and 4 bytes for supplementary characters outside BMP (21-bit).
- The 128 ASCII characters (basic Latin letters, digits, and punctuation signs) utilize ane byte. Almost European and Middle East characters utilize a 2-byte sequence, which includes extended Latin letters (with tilde, macron, acute, grave and other accents), Greek, Armenian, Hebrew, Arabic, and others. Chinese, Japanese and Korean (CJK) utilise three-byte sequences.
- All the bytes, except the 128 ASCII characters, have a leading
'1'chip. In other words, the ASCII bytes, with a leading'0'flake, can be identified and decoded easily.
Example: 您好 (Unicode: 60A8H 597DH)
Unicode (UCS-2) is 60A8H = 0110 0000 10 101000B ⇒ UTF-eight is 11100110 10000010 10101000B = E6 82 A8H Unicode (UCS-2) is 597DH = 0101 1001 01 111101B ⇒ UTF-8 is 11100101 10100101 10111101B = E5 A5 BDH
UTF-16 (Unicode Transformation Format - 16-scrap)
UTF-16 is a variable-length Unicode character encoding scheme, which uses ii to 4 bytes. UTF-xvi is not commonly used. The transformation table is as follows:
| Unicode | UTF-xvi Code | Bytes |
|---|---|---|
| xxxxxxxx xxxxxxxx | Same every bit UCS-2 - no encoding | two |
| 000uuuuu zzzzyyyy yyxxxxxx (uuuuu≠0) | 110110ww wwzzzzyy 110111yy yyxxxxxx (wwww = uuuuu - 1) | iv |
Have note that for the 65536 characters in BMP, the UTF-16 is the aforementioned as UCS-2 (2 bytes). However, iv bytes are used for the supplementary characters exterior the BMP.
For BMP characters, UTF-16 is the same as UCS-2. For supplementary characters, each character requires a pair xvi-scrap values, the first from the high-surrogates range, (\uD800-\uDBFF), the 2d from the low-surrogates range (\uDC00-\uDFFF).
UTF-32 (Unicode Transformation Format - 32-scrap)
Aforementioned every bit UCS-4, which uses iv bytes for each grapheme - unencoded.
Formats of Multi-Byte (e.thousand., Unicode) Text Files
Endianess (or byte-order): For a multi-byte character, you need to take care of the order of the bytes in storage. In big endian, the most significant byte is stored at the retentiveness location with the lowest address (large byte showtime). In little endian, the most pregnant byte is stored at the retentiveness location with the highest address (niggling byte first). For example, 您 (with Unicode number of 60A8H) is stored as 60 A8 in big endian; and stored as A8 threescore in petty endian. Big endian, which produces a more readable hex dump, is more commonly-used, and is often the default.
BOM (Byte Order Mark): BOM is a special Unicode grapheme having code number of FEFFH, which is used to differentiate big-endian and little-endian. For big-endian, BOM appears as FE FFH in the storage. For little-endian, BOM appears equally FF FEH. Unicode reserves these 2 code numbers to prevent information technology from crashing with another character.
Unicode text files could take on these formats:
- Big Endian: UCS-2BE, UTF-16BE, UTF-32BE.
- Fiddling Endian: UCS-2LE, UTF-16LE, UTF-32LE.
- UTF-16 with BOM. The first character of the file is a BOM character, which specifies the endianess. For large-endian, BOM appears equally
FE FFHin the storage. For little-endian, BOM appears asFF FEH.
UTF-8 file is always stored as large endian. BOM plays no part. However, in some systems (in particular Windows), a BOM is added as the first character in the UTF-8 file as the signature to identity the file equally UTF-8 encoded. The BOM character (FEFFH) is encoded in UTF-8 every bit EF BB BF. Calculation a BOM as the first graphic symbol of the file is not recommended, equally it may be incorrectly interpreted in other system. Y'all can have a UTF-8 file without BOM.
Formats of Text Files
Line Delimiter or End-Of-Line (EOL): Sometimes, when you use the Windows NotePad to open a text file (created in Unix or Mac), all the lines are joined together. This is because different operating platforms use different character equally the so-called line delimiter (or finish-of-line or EOL). Two non-printable control characters are involved: 0AH (Line-Feed or LF) and 0DH (Carriage-Return or CR).
- Windows/DOS uses
OD0AH(CR+LF or "\r\n") every bit EOL. - Unix and Mac use
0AH(LF or "\n") only.
End-of-File (EOF): [TODO]
Windows' CMD Codepage
Character encoding scheme (charset) in Windows is called codepage. In CMD shell, you can issue command "chcp" to display the current codepage, or "chcp codepage-number" to change the codepage.
Accept annotation that:
- The default codepage 437 (used in the original DOS) is an viii-bit character set called Extended ASCII, which is different from Latin-1 for code numbers above 127.
- Codepage 1252 (Windows-1252), is non exactly the same as Latin-one. Information technology assigns code number 80H to 9FH to messages and punctuation, such as smart single-quotes and double-quotes. A common problem in browser that brandish quotes and apostrophe in question marks or boxes is because the page is supposed to exist Windows-1252, only mislabelled equally ISO-8859-ane.
- For internationalization and chinese character set up: codepage 65001 for UTF8, codepage 1201 for UCS-2BE, codepage 1200 for UCS-2LE, codepage 936 for chinese characters in GB2312, codepage 950 for chinese characters in Big5.
Chinese Character Sets
Unicode supports all languages, including asian languages like Chinese (both simplified and traditional characters), Japanese and Korean (collectively called CJK). There are more than twenty,000 CJK characters in Unicode. Unicode characters are frequently encoded in the UTF-8 scheme, which unfortunately, requires three bytes for each CJK character, instead of two bytes in the unencoded UCS-2 (UTF-16).
Worse nevertheless, there are also various chinese character sets, which is not compatible with Unicode:
- GB2312/GBK: for simplified chinese characters. GB2312 uses ii bytes for each chinese graphic symbol. The most significant bit (MSB) of both bytes are set to one to co-exist with 7-fleck ASCII with the MSB of 0. At that place are near 6700 characters. GBK is an extension of GB2312, which include more characters as well as traditional chinese characters.
- BIG5: for traditional chinese characters BIG5 also uses two bytes for each chinese character. The near significant bit of both bytes are also set to ane. BIG5 is not compatible with GBK, i.e., the aforementioned code number is assigned to different character.
For example, the globe is made more interesting with these many standards:
| Standard | Characters | Codes | |
|---|---|---|---|
| Simplified | GB2312 | 和谐 | BACD D0B3 |
| UCS-2 | 和谐 | 548C 8C10 | |
| UTF-8 | 和谐 | E5928C E8B090 | |
| Traditional | BIG5 | 和諧 | A94D BFD3 |
| UCS-2 | 和諧 | 548C 8AE7 | |
| UTF-8 | 和諧 | E5928C E8ABA7 |
Notes for Windows' CMD Users: To display the chinese character correctly in CMD shell, you need to cull the correct codepage, e.thousand., 65001 for UTF8, 936 for GB2312/GBK, 950 for Big5, 1201 for UCS-2BE, 1200 for UCS-2LE, 437 for the original DOS. You can use command "chcp" to display the current code page and control "chcp codepage_number " to change the codepage. You also accept to choose a font that can display the characters (e.thou., Courier New, Consolas or Lucida Panel, Not Raster font).
Collating Sequences (for Ranking Characters)
A string consists of a sequence of characters in upper or lower cases, e.k., "apple", "Boy", "Cat". In sorting or comparing strings, if we order the characters according to the underlying lawmaking numbers (east.g., US-ASCII) character-by-character, the gild for the example would be "BOY", "apple", "Cat" because uppercase letters accept a smaller code number than lowercase letters. This does not agree with the so-called dictionary club, where the same uppercase and lowercase letters take the same rank. Another common problem in ordering strings is "10" (ten) at times is ordered in front of "1" to "9".
Hence, in sorting or comparing of strings, a and so-called collating sequence (or collation) is frequently defined, which specifies the ranks for messages (uppercase, lowercase), numbers, and special symbols. There are many collating sequences available. It is entirely up to you to choose a collating sequence to run into your application'due south specific requirements. Some case-insensitive lexicon-guild collating sequences have the same rank for aforementioned uppercase and lowercase messages, i.e., 'A', 'a' ⇒ 'B', 'b' ⇒ ... ⇒ 'Z', 'z'. Some case-sensitive dictionary-society collating sequences put the uppercase letter earlier its lowercase counterpart, i.e., 'A' ⇒'B' ⇒ 'C'... ⇒ 'a' ⇒ 'b' ⇒ . Typically, infinite is ranked before digits 'c'...'0' to '9', followed by the alphabets.
Collating sequence is oft linguistic communication dependent, as different languages use different sets of characters (e.g., á, é, a, α) with their own orders.
For Coffee Programmers - java.nio.Charset
JDK ane.iv introduced a new coffee.nio.charset bundle to back up encoding/decoding of characters from UCS-2 used internally in Coffee program to any supported charset used by external devices.
Example: The following program encodes some Unicode texts in various encoding scheme, and display the Hex codes of the encoded byte sequences.
import coffee.nio.ByteBuffer; import java.nio.CharBuffer; import java.nio.charset.Charset; public class TestCharsetEncodeDecode { public static void main(String[] args) { String[] charsetNames = {"U.s.-ASCII", "ISO-8859-1", "UTF-viii", "UTF-16", "UTF-16BE", "UTF-16LE", "GBK", "BIG5"}; Cord message = "Hullo,您好!"; System.out.printf("%10s: ", "UCS-2"); for (int i = 0; i < message.length(); i++) { Organization.out.printf("%04X ", (int)bulletin.charAt(i)); } Arrangement.out.println(); for (Cord charsetName: charsetNames) { Charset charset = Charset.forName(charsetName); System.out.printf("%10s: ", charset.proper name()); ByteBuffer bb = charset.encode(message); while (bb.hasRemaining()) { System.out.printf("%02X ", bb.get()); } System.out.println(); bb.rewind(); } } } UCS-two: 0048 0069 002C 60A8 597D 0021 US-ASCII: 48 69 2C 3F 3F 21 ISO-8859-1: 48 69 2C 3F 3F 21 UTF-8: 48 69 2C E6 82 A8 E5 A5 BD 21 UTF-16: FE FF 00 48 00 69 00 2C 60 A8 59 7D 00 21 UTF-16BE: 00 48 00 69 00 2C threescore A8 59 7D 00 21 UTF-16LE: 48 00 69 00 2C 00 A8 60 7D 59 21 00 GBK: 48 69 2C C4 FA BA C3 21 Big5: 48 69 2C B1 7A A6 6E 21
For Java Programmers - char and String
The char data blazon are based on the original 16-bit Unicode standard called UCS-ii. The Unicode has since evolved to 21 bits, with code range of U+0000 to U+10FFFF. The set of characters from U+0000 to U+FFFF is known as the Bones Multilingual Plane (BMP). Characters higher up U+FFFF are called supplementary characters. A 16-scrap Coffee char cannot agree a supplementary character.
Think that in the UTF-sixteen encoding scheme, a BMP characters uses ii bytes. It is the aforementioned as UCS-2. A supplementary character uses 4 bytes. and requires a pair of xvi-bit values, the kickoff from the loftier-surrogates range, (\uD800-\uDBFF), the second from the low-surrogates range (\uDC00-\uDFFF).
In Coffee, a String is a sequences of Unicode characters. Coffee, in fact, uses UTF-xvi for String and StringBuffer. For BMP characters, they are the same as UCS-two. For supplementary characters, each characters requires a pair of char values.
Coffee methods that accept a 16-flake char value does not support supplementary characters. Methods that accept a 32-chip int value back up all Unicode characters (in the lower 21 $.25), including supplementary characters.
This is meant to be an academic discussion. I take withal to encounter the use of supplementary characters!
Displaying Hex Values & Hex Editors
At times, you may demand to display the hex values of a file, specially in dealing with Unicode characters. A Hex Editor is a handy tool that a skillful programmer should possess in his/her toolbox. There are many freeware/shareware Hex Editor available. Endeavour google "Hex Editor".
I used the followings:
- NotePad++ with Hex Editor Plug-in: Open-source and free. You tin toggle betwixt Hex view and Normal view by pushing the "H" button.
- PSPad: Freeware. You can toggle to Hex view past choosing "View" card and select "Hex Edit Manner".
- TextPad: Shareware without expiration flow. To view the Hex value, you need to "open" the file by choosing the file format of "binary" (??).
- UltraEdit: Shareware, not free, 30-day trial merely.
Let me know if you take a better choice, which is fast to launch, easy to utilise, can toggle between Hex and normal view, free, ....
The following Java plan can be used to display hex code for Java Primitives (integer, graphic symbol and floating-signal):
1 ii 3 four 5 6 seven 8 ix 10 11 12 xiii 14 fifteen xvi 17 18 xix xx 21 22 23 24 25 26 27 28 29 30 | public class PrintHexCode { public static void main(String[] args) { int i = 12345; System.out.println("Decimal is " + i); Arrangement.out.println("Hex is " + Integer.toHexString(i)); Organisation.out.println("Binary is " + Integer.toBinaryString(i)); Organization.out.println("Octal is " + Integer.toOctalString(i)); System.out.printf("Hex is %10\northward", i); System.out.printf("Octal is %o\n", i); char c = 'a'; Organization.out.println("Grapheme is " + c); Organization.out.printf("Character is %c\northward", c); Arrangement.out.printf("Hex is %ten\n", (short)c); Organization.out.printf("Decimal is %d\northward", (short)c); bladder f = 3.5f; System.out.println("Decimal is " + f); Organization.out.println(Bladder.toHexString(f)); f = -0.75f; System.out.println("Decimal is " + f); System.out.println(Float.toHexString(f)); double d = 11.22; Arrangement.out.println("Decimal is " + d); Organization.out.println(Double.toHexString(d)); } } |
In Eclipse, you can view the hex code for integer primitive Coffee variables in debug way as follows: In debug perspective, "Variable" panel ⇒ Select the "carte" (inverted triangle) ⇒ Coffee ⇒ Coffee Preferences... ⇒ Primitive Brandish Options ⇒ Check "Brandish hexadecimal values (byte, short, char, int, long)".
Summary - Why Carp about Data Representation?
Integer number one, floating-point number 1.0 character symbol 'one', and string "1" are totally dissimilar inside the estimator memory. You demand to know the divergence to write good and high-performance programs.
- In 8-bit signed integer, integer number
1is represented as00000001B. - In 8-bit unsigned integer, integer number
1is represented as00000001B. - In xvi-bit signed integer, integer number
1is represented as00000000 00000001B. - In 32-scrap signed integer, integer number
1is represented as000000000000000000000000 00000001B. - In 32-fleck floating-point representation, number
1.0is represented as0 01111111 0000000 00000000 00000000B, i.e.,S=0,E=127,F=0. - In 64-bit floating-point representation, number
1.0is represented as0 01111111111 0000 00000000 00000000 00000000 00000000 00000000 00000000B, i.eastward.,S=0,East=1023,F=0. - In 8-bit Latin-1, the graphic symbol symbol
'1'is represented equally00110001B(or31H). - In sixteen-scrap UCS-2, the grapheme symbol
'1'is represented as00000000 00110001B. - In UTF-8, the grapheme symbol
'1'is represented as00110001B.
If you "add" a 16-bit signed integer 1 and Latin-1 graphic symbol '1' or a string "1", yous could get a surprise.
Exercises (Information Representation)
For the following 16-flake codes:
0000 0000 0010 1010; 1000 0000 0010 1010;
Requite their values, if they are representing:
- a 16-bit unsigned integer;
- a xvi-bit signed integer;
- 2 viii-bit unsigned integers;
- two viii-bit signed integers;
- a 16-bit Unicode characters;
- 2 viii-bit ISO-8859-1 characters.
Ans: (1) 42, 32810; (two) 42, -32726; (3) 0, 42; 128, 42; (4) 0, 42; -128, 42; (5) '*'; '耪'; (6) NUL, '*'; PAD, '*'.
REFERENCES & RESOURCES
- (Floating-Point Number Specification) IEEE 754 (1985), "IEEE Standard for Binary Floating-Point Arithmetic".
- (ASCII Specification) ISO/IEC 646 (1991) (or ITU-T T.50-1992), "Data technology - 7-bit coded character set for information interchange".
- (Latin-I Specification) ISO/IEC 8859-1, "Data applied science - 8-fleck single-byte coded graphic character sets - Office ane: Latin alphabet No. 1".
- (Unicode Specification) ISO/IEC 10646, "It - Universal Multiple-Octet Coded Character Ready (UCS)".
- Unicode Consortium @ http://www.unicode.org.
Source: https://www3.ntu.edu.sg/home/ehchua/programming/java/datarepresentation.html
{kind=link}
Post a Comment for "how to draw a 3d floating number 8"